How Compiler Explorer Works in 2025
Written with LLM assistance.
Details at end.
Ever wondered what happens when you hit that compile button on Compiler Explorer? Last week I was looking at our metrics dashboard, and then I realised: we now do 92 million compilations a year. That’s 1.8 million a week…for a site that started as a hacky way to justify to my boss that it would be OK to turn on C++11 features1, that’s not bad.
I thought it might be fun to share how this all works. Not just a high-level summary, but some of the details of keeping 3000+ different compiler versions2 running smoothly across 81 programming languages. It’s a lot more warty than you might imagine (and than I’d like).
What actually happens when you stop typing
When you type some code into Compiler Explorer, here’s what actually happens (for a simple x86-based compilation):
- You type into the Monaco editor (the same one VS Code uses)
- Your code wings its way via CloudFront5 and a load balancer
- The load balancer determines which cluster this request is for, and picks a healthy instance to send it to4
- That server queues your compilation request (currently up to 2 concurrent compilations per instance)
- Here’s where it gets interesting: nsjail creates a tiny prison for your code
- The compiler is run with appropriate language- and compiler-dependent flags in this sandbox, generates output
- Results get filtered (removing the boring bits), source lines are attributed, and it’s all sent back as a JSON response3
- Your browser renders the assembly, and you go “ooh, how clever is this compiler!”

The complete request flow from your browser to compiler and back.
Generated from this .dot file.
As load comes and goes, we scale up the number of instances in each cluster: so if we get a flurry of Windows compiler requests, then within a few minutes our fleet should have scaled up to meet the demand. We keep it simple: we just try and keep the average CPU load below a threshold. We’ve kicked around more sophisticated ideas but this is simple and supported out-of-the-box in AWS.
Not getting hacked by random people on the internet
We let random people run arbitrary code on our machine, which seems like a terrible mistake. GitHub’s own “security analyser” keeps flagging this during PRs, in fact. That used to keep me up at night, and for good reason. We’ve had some proper “oh no” moments over the years.
Back when we only had basic Docker isolation, someone found a way to crash Clang in just the right way that it left a built .o file in a temporary location - and helpfully printed out the path. A subsequent request could then load that file with -fplugin=/tmp/that/place.o, giving them arbitrary code execution in the compiler. Not ideal.
More recently, we had a clever attack involving CMake rules that would symbolically link outputs to sensitive files like /etc/passwd in the output directory as example.s. The CMake runs in our strict nsjail, BUT the code that processes compiler output runs under the web server’s account. So our web server would dutifully read the “file” (unaware it’s a symlink) and send back the contents. Oops6. We now run everything on mounts with nosymfollow (no symbolic link following) which should protect us going forward.
Enter nsjail, Google’s lightweight process isolation tool that’s basically a paranoid security guard for processes.
We configure nsjail with two personalities:
etc/nsjail/execute.cfg- for actually running your compiled programsetc/nsjail/sandbox.cfg- for the compilation process itself
It gives us:
- Linux namespaces (all of them - UTS, MOUNT, PID, IPC, NET, USER, CGROUPS)7
- Resource limits (file handles, memory, and a 20-second timeout because infinite loops are only fun in theory)8
- Filesystem isolation (your code can’t read sensitive files, sorry attackers)
This paranoid approach means we can now actually run your programs, not just compile them. That’s a massive improvement from the early days when we’d just show you assembly and hope you could imagine what it did9.
Yes, we really do have 4TB of compilers
How do you manage nearly 4TB of compilers? Very carefully, and with a lot of Python and shell scripts. The requests we get for new compilers range from sensible to wonderfully niche. One that sticks out is supporting the oldest compilable C version: GCC 1.27 (yes, from 1987). Another ongoing quest is adding the “cfront” compiler, specifically the one used on early Acorn computers for the then-nascent ARM architecture10.
One of our core principles is that we never retire compiler versions. Once a compiler goes up on Compiler Explorer, it stays there forever. This might seem excessive, but it means that URLs linking to specific compiler versions will always work. Ten years from now, that Stack Overflow answer showing a GCC 4.8 bug will still compile on CE exactly as it did when posted. It’s our small contribution to fighting link rot11, even if it means hoarding terabytes of compilers.
We’ve got two main tools for managing this madness:
- bin/ce_install - This installs compilers and libraries:
- Installs compilers to
/opt/compiler-explorerfrom a variety of sources (mostly our own builds, stored on S3) - Handles everything from bleeding-edge trunk builds to that one version of GCC from 2006 someone definitely needs
- Builds squashfs images for stable compilers
- Installs compilers to
- bin/ce - This handles deployments:
- Sets which versions are deployed to which environment (x86, arm, windows production, staging, beta)
- Manages environment lifecycles
- Handles rolling updates
Why squashfs saved our bacon
One of the issues with having so many compilers is that we can’t install them individually on each machine: the VMs don’t work well with such huge disk images. Fairly early on we had to accept that the compilers needed to live on some kind of shared storage, and Amazon has the Elastic File System (EFS) which is their “infinitely sized” NFS system:
admin-node~ $ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p1 24G 18G 6.0G 75% /
tmpfs 969M 0 969M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
efs.amazonaws.com:/ 8.0E 3.9T 8.0E 1% /efs
OK, apparently not infinite, but 8 exabytes ought to be enough for anyone, right?
The issue with any network file system is latency. And that latency adds up quickly with compilation: C-like languages love to include tons of tiny little files. In fact, we used to have issues compiling any Boost code as we would time out while the preprocessor was still running. Our initial solution was to have Boost rsync onto the machine locally at boot-up, but as we supported more and more compilers and libraries, that wouldn’t scale.
So in 2020, we came up with a decent(ish) hack: we built squashfs images for all our major compilers, and then mounted them “over the top” of NFS. The images themselves we also stored on NFS, so this seems like a pointless thing to do but it works pretty well!12
Building fresh compilers every night
Perhaps a surprising thing we do: we build and install many compilers every single day. We use the excellent terraform-aws-github-runner project to configure our AWS-based GitHub Actions runners13, but the Docker infrastructure and compiler orchestration is all our own creation built on top.
The magic happens across several GitHub repos:
- compiler-workflows - The orchestration system with a
compilers.yamlfile that drives the daily builds - gcc-builder - Docker image to build GCC variants including trunk and experimental branches
- clang-builder - Similarly, for clang
- misc-builder - For the weird and wonderful compilers that don’t fit elsewhere
- We have some other ”*-builder”s for things like COBOL and .NET too
Every night, our GitHub Actions spin up and build:
- GCC trunk
- Clang trunk
- Many experimental branches (reflections, contracts, coroutines - all the fun stuff)
- Some other languages’ nightly builds
The timing of all this is… well, let’s call it “organic”. GitHub Actions are scheduled to build at midnight UTC, but they queue up on our limited build infrastructure. There’s a separate workflow that does the install at 5:30am. There’s currently zero synchronisation between these two systems, which means sometimes we’re installing yesterday’s builds, sometimes today’s, and occasionally we get lucky and everything lines up. It’s on the TODO list to fix, right after the other 900+ items.
It’s like Christmas every morning, except instead of presents, we get fresh compiler builds. You can see our build status on GitHub.

A wall of 4,724 compilers across 81 languages - from GCC 1.27 (1987) to today.
This visualisation is generated dynamically from our API!
Making it work on Windows, ARM, and GPUs too
Gone are the days when “Linux x86-64” was good enough for everyone. Now we support:
- Windows: At least 2 spot instances running MSVC and friends. Getting Windows compilers to play nicely with our Linux-centric infrastructure has been an adventure. We’re still learning how best to integrate Windows - none of the core team are Windows security experts, but we’re getting there.
- ARM machines: Native ARM64 execution for the growing number of ARM-based systems out there.
- GPU Instances: 2 instances with actual NVIDIA GPUs. We worked with our friends at NVIDIA (now a corporate sponsor - thank you NVIDIA!) to get drivers and toolchains working properly.14
Everything runs from AWS’s us-east-1 region. Yes, that means if you’re compiling from Australia or Europe, your code takes a scenic route across the Pacific or Atlantic. We’ve thought about multi-region deployment, but the complexity of keeping that amount of compilers in sync across the globe makes my head hurt. For now, we just let CloudFront’s edge caching handle the static content and apologise to our friends in far-flung places for the extra latency.
Keeping an eye on things
Some statistics about our current setup:
- 3.9 terabytes of compilers, libraries, and tools
- Up to 30+ EC2 instances (EC2 instances are virtual machines)
- 4,724 compiler versions
- 1,982,662 short links saved (and as of recently, ~14k ex-goo.gl links)
- 1.8 million compilations per week
That’s around 90 million compilations a year, so we keep an eye on things with:
- Grafana agents on every instance
- Prometheus for metrics collection
- Loki for log aggregation
- CloudWatch for AWS metrics and auto-scaling triggers
We have public dashboards so you can see our metrics in real-time.
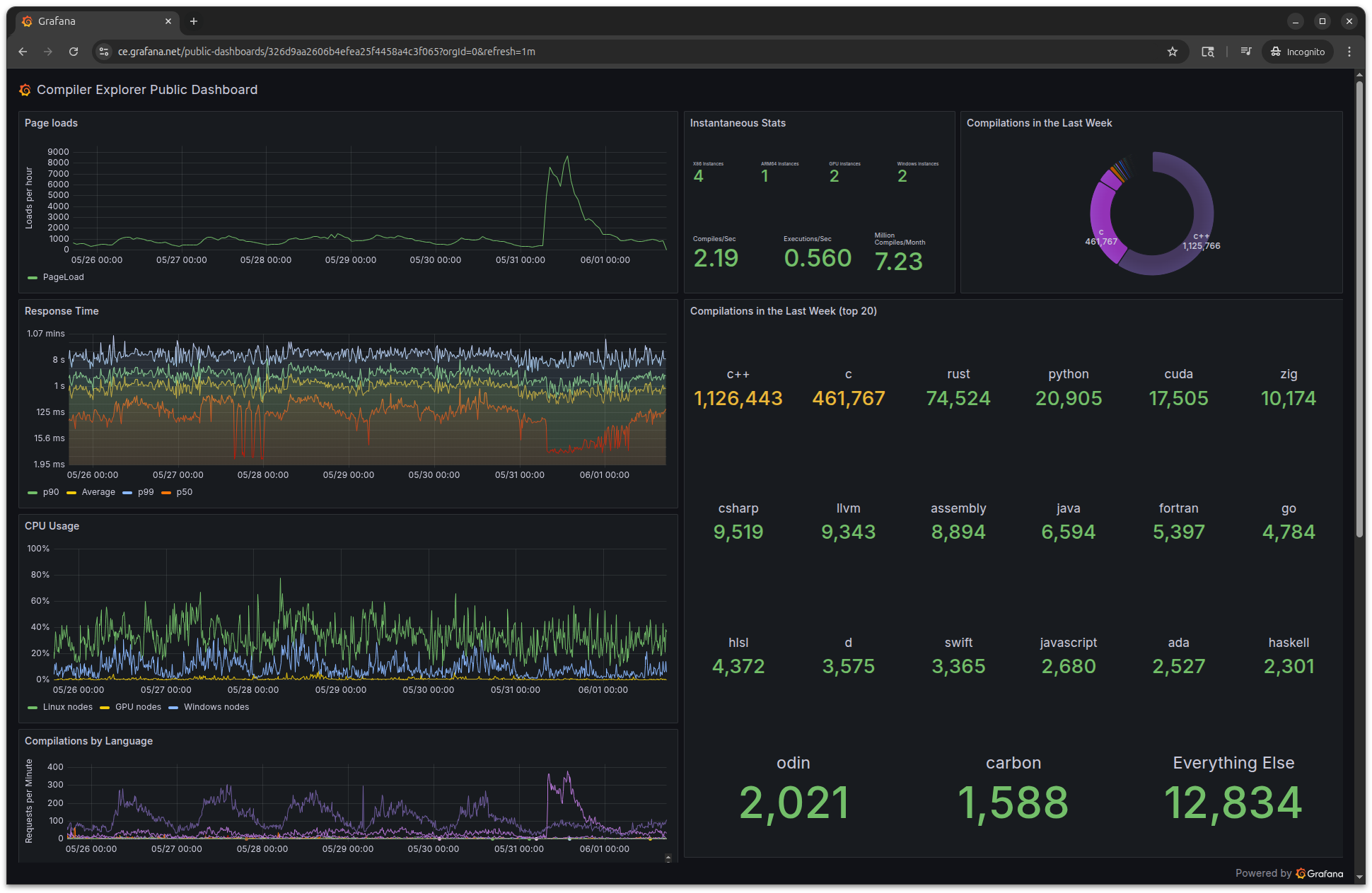
Our public dashboard at stats.compiler-explorer.com if you're curious about what's going on.
Keeping costs down is tricky. We’re behind on this front, choosing to spend our limited volunteer time on adding features and compilers rather than reducing costs. We use spot instances where we can, and implement caching to avoid redundant compilations: caching in the browser, in each instance in an LRU cache, and then also on S3 using a daily-expiring content-addressable approach.
Our Patreon supporters, GitHub sponsors and commercial sponsors cover the bills with enough slack to make this sustainable. Right now, Compiler Explorer costs around $3,00015 a month (including AWS, monitoring, Sentry for errors, Grafana, and other expenses). I’m hoping to find a way to be more transparent about the costs (if you’re a Patron, then you know I usually do a post about this once a year).
It all works pretty well these days. We haven’t had a major outage from traffic spikes in years - the auto-scaling just quietly does its job.
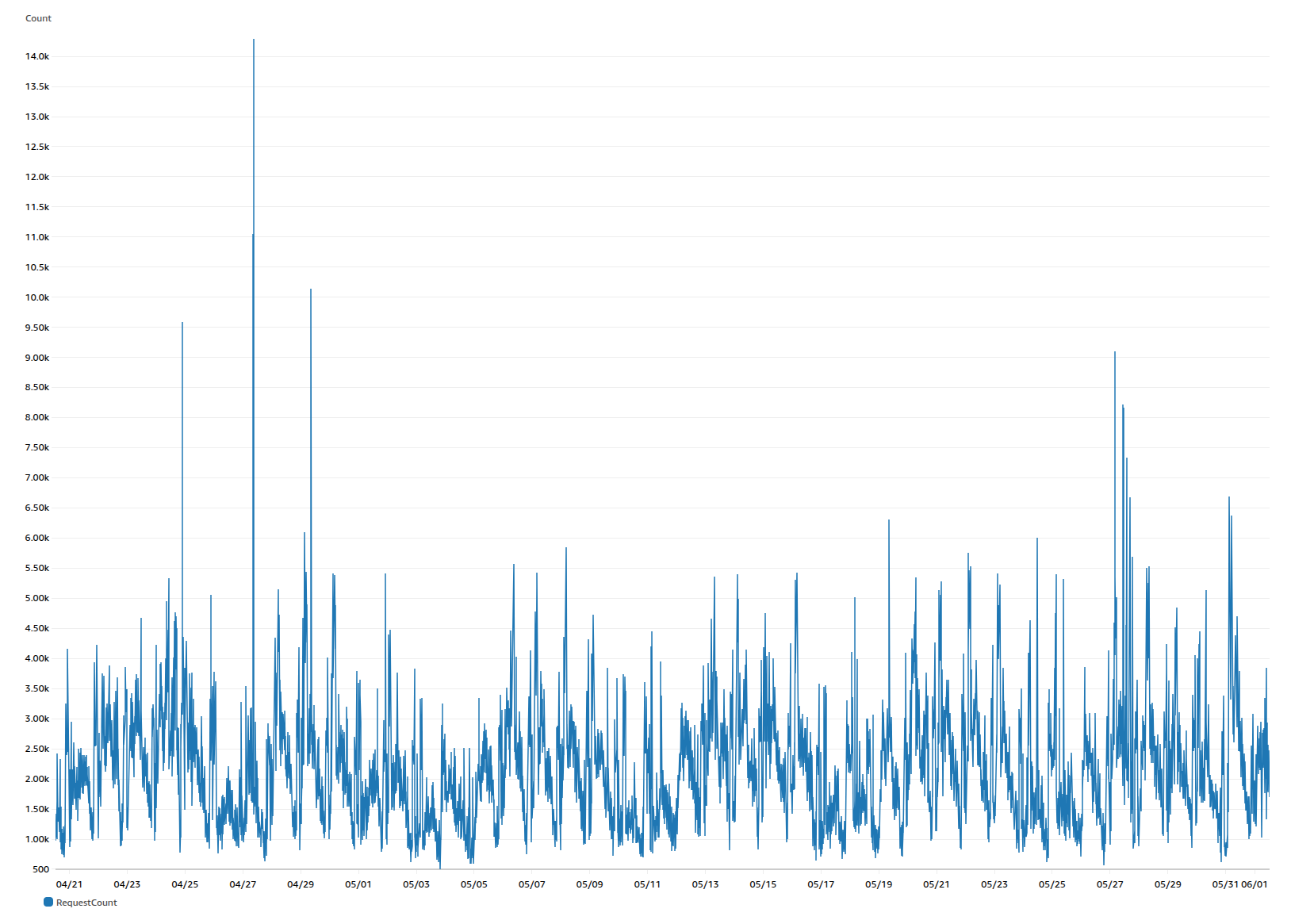
Our traffic over the last 6 weeks - mostly steady-state with regular patterns, but that spike on April 27th shows the auto-scaling handling a 4x traffic surge without breaking a sweat.
These days, our traffic is a bit more predictable with regular daily and weekly patterns rather than the wild viral spikes of the early days.
What’s Next?
What we have today started from that first hacky prototype. Every decision was made to solve a real problem:
nsjailcame about because people kept trying to break things- Daily builds started because manually updating compilers was painful
- We added multi-architecture support because users kept asking
- We moved to Typescript from pure Javascript because we like types16
Looking forward, I’m currently working on an opt-in AI explanation tool panel. If I can get it working well enough, it should be deployed in the next few weeks. You can read my thoughts on AI in coding if you’re curious about the approach.
Eventually I’d like to add:
- User accounts for managing short links (at least, if I can be sure enough of the privacy implications and regulatory burden)
- More architectures (particularly RISC-V)
- CPU performance analysis visualisation (been wanting this for 6+ years)
Some things I wish I’d done differently:
Early decisions that haunt us: Our save format is tightly coupled to the GoldenLayout library we use for the UI. This means we have to be super careful upgrading GoldenLayout to ensure we can still load older links. When you promise “URLs that last forever,” even your JavaScript library choices become permanent fixtures.
The link shortener mess: A long time ago we used short links that looked like godbolt.org/g/abc123. They were actually wrappers around Google’s goo.gl shortener. When Google announced they were killing it, we had to scramble to preserve 12,000+ legacy links. Never trust a third-party service with your core infrastructure17 - lesson learned the hard way.
Infrastructure cruft: I wish I’d laid out our NFS directory structure better from the start. I wish we had a better story for configuration management across thousands of compilers. Multi-cluster support and service discovery remain ongoing challenges. Oh, and deployment? It’s completely ad hoc right now - we deploy updates to each cluster manually and separately. We’re working on blue/green deployment to make deploys less problematic, and ideally we’ll automate more of this process. At least when things do break, the auto-scaling group replaces the dead instances and I get a friendly 3am text message.
The fact that this whole thing works at all still amazes me sometimes. From a weekend project to infrastructure that serves thousands of developers18 - it’s been quite the journey.
Thanks
None of this would work without the amazing team of contributors and administrators who keep the lights on. Huge thanks to:
Partouf (Patrick Quist) - Basically keeps CE running. They are fantastic and I don’t know what CE would do without them.
Core team: Jeremy Rifkin, Marc Poulhiès, Ofek Shilon, Mats Jun Larsen, Abril Rincón Blanco, and Austin Morton are all huge contributors and core developers.
Community heroes: Miguel Ojeda, Johan Engelen, narpfel, Kevin Jeon and many, many more.
- The compiler maintainers whose amazing work we’re privileged to showcase
- Our corporate sponsors
- Everyone who supports us on Patreon and GitHub Sponsors
- You, for using the site and making all this infrastructure worthwhile
Questions? Complaints? Compiler versions we’re missing? Drop by our Discord, or find me on Bluesky or Mastodon.
Want to support Compiler Explorer? Check out our Patreon or GitHub Sponsors. Those AWS bills don’t pay themselves.
Disclaimer
This article was a collaboration between a human and an LLM. The LLM was set off to research the codebase and internet for things that have changed since 2016 (the last time I wrote a “how it works”). Then I used that to create a framework for an article. I did the first few edits, then got LLM assistance in looking for mistakes and typos, and some formatting assistance. The LLM wrote the dot file and the python code that generates the “wall” of compiler stats.
The LLM also reminded me that I usually put a disclaimer at the end of my articles saying that I used AI assistance, which I had forgotten to do. Thanks, Claude.
-
Jordan, I’m sorry - this tale has taken on a life of its own. Compiler Explorer started as a shell script running
watch "gcc -S example.cpp -O1 | c++filt | grep -v ..."in ascreensession with avimpanel on one side and the script on the other. I was trying to show that C++11 range-basedforloops generated identical code to their non-range-based equivalents. ↩ -
4,724 but that’s sort of cheating, double counting the same version of the GNU Compiler Collection for C, C++, Fortran etc. ↩
-
We have a whole RESTful API if you want to look for yourself ↩
-
The load balancer checks the health of each node by putting a
/healthcheckrequest through it. If it fails, we shut down the virtual machine it’s on, and fire up a new one. And I get a text message…
↩
-
We employ Amazon’s WAF too to help with denial of service attacks. We have very simple and very high rate limits per IP; we used to be more strict but C++ trainers would hit the limits when teaching classes where the whole class was behind a conference’s NAT and so appeared like a single IP. ↩
-
In fairness,
/etc/passwdhasn’t been a security issue for 40+ years, and our web server runs as a very unprivileged account, but still worth fixing! ↩ -
Think of namespaces as different views of the system - each process thinks it has its own hostname (UTS), filesystem (MOUNT), process tree (PID), etc. It’s like giving each compilation its own tiny Linux universe to play in. ↩
-
Obviously getting an error message “compilation timed out” isn’t a great user experience, but hopefully you don’t see that too often. ↩
-
Though to be fair, if you’re using Compiler Explorer, you probably can imagine what assembly does. You lovely people. ↩
-
My philosophy is “more is better” - if you want a compiler added, PRs are welcome! ↩
-
As I mention elsewhere, not everyone has this focus… ↩
-
Normally NFS caches data locally, but it still has to validate that cached metadata is fresh by checking with the server (via attribute caching with default timeouts). Even if your file data is cached, the kernel still pays the network latency cost to verify it hasn’t changed on the remote end. By mounting squashfs images through loopback devices, we effectively “launder” away the NFS-ness - the squashfs driver sees what looks like a local block device and caches blocks normally, without the constant metadata validation round trips. The kernel is blissfully unaware that “behind” those cached blocks is an NFS file that could theoretically change. For our immutable compiler images this is a huge boon, and this change made a big improvement in compilation speed. At the cost of mounting 2000 squashfs images at startup (though we’re looking at ways of improving this now). ↩
-
Using GitHub’s own runners isn’t enough: compiling clang and GCC takes an awful lot of CPU time, and in order to get them to complete compiling in a reasonable amount of time, we have to use pretty beefy machines. When we set this all up, GitHub didn’t have their “pay for faster machines” option, but honestly it’s nicer to use our “own” hardware here anyway. ↩
-
These instances cost a small fortune to run, but being able to see the results of running GPU code makes it worthwhile. ↩
-
It’s amazing to think I used to cover the costs all by myself (thanks to my wife for being so supportive of me in that) - I’m glad Jason Turner talked me in to making a Patreon page. ↩
-
Even though at heart I’m a jumped-up assembly programmer, I have learned to love the type system of C++ and the protections that brings. CE was originally written in Javascript which has no types to speak of, and we’re still suffering from that now. We moved to Typescript, which is a strongly-typed language that transpiles to Javascript, and things have improved a lot. ↩
-
I mean, we’re a bit stuck with AWS, but in principle we could move, and at least we own all our data there. ↩
-
I really don’t know how many developers use Compiler Explorer: we purposefully don’t have the kind of tracking that could tell us. But, it’s at least in the thousands I think. ↩